RAG搜索中Embedding服务的应用与实践
RAG搜索中Embedding服务的应用与实践
夏佳怡引言
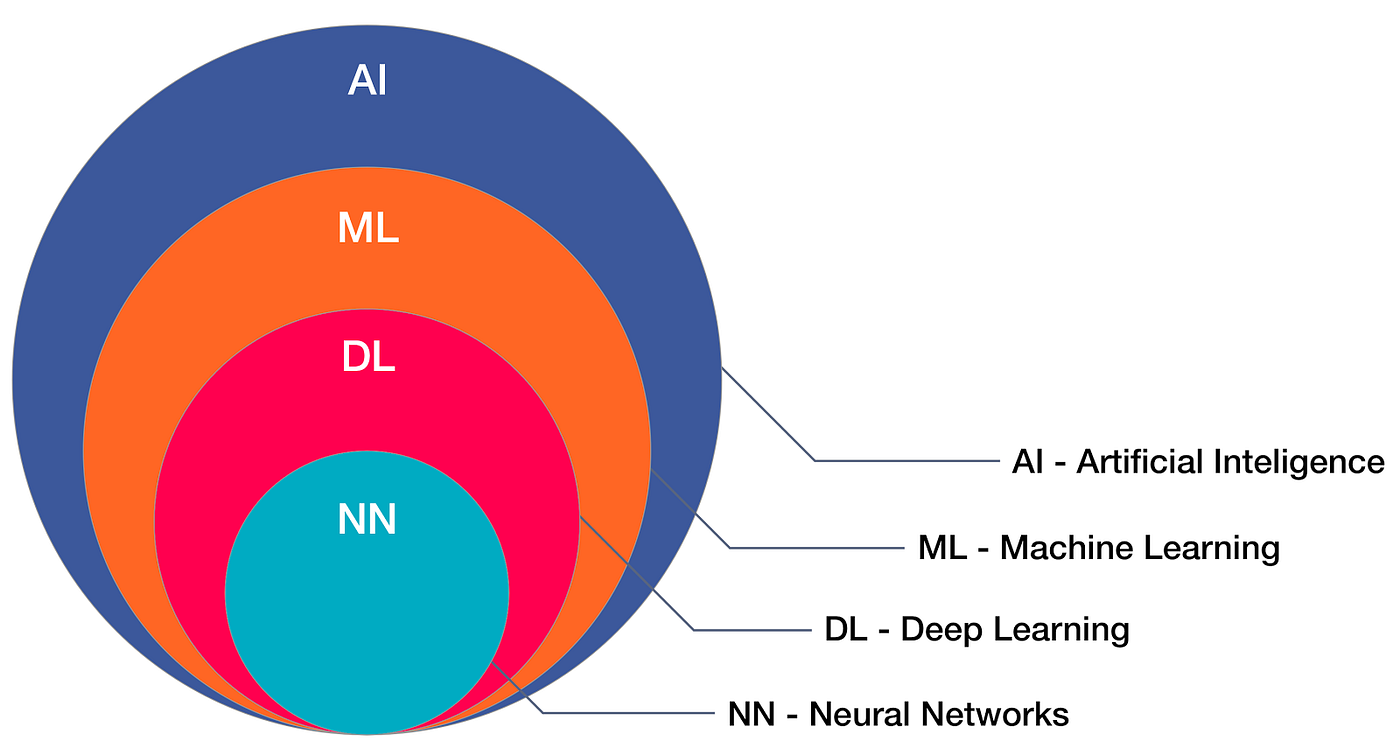
在当前AI快速发展的背景下,RAG(Retrieval-Augmented Generation)技术因其能够有效结合外部知识与大语言模型而备受关注。本文将深入探讨RAG系统中的关键组件——Embedding服务,从理论到实践,帮助读者全面理解和应用这一技术。
RAG技术概述
工作原理
RAG技术通过以下步骤提升生成模型的表现:
- 知识库构建:将文档分块并通过Embedding服务转换为向量表示
- 相似度检索:基于用户查询检索相关文档片段
- 上下文融合:将检索到的内容作为上下文提供给大语言模型
- 答案生成:模型基于上下文生成准确的回答
技术优势
- 提供可溯源的知识支持
- 降低模型幻觉概率
- 支持知识的实时更新
- 减少训练成本
Embedding服务详解
核心技术原理
Embedding是将文本转换为稠密向量的过程,主要包括:
文本预处理
- 分词和标准化
- 特殊字符处理
- 长文本切分
向量生成
- 模型前向计算
- 维度归一化
- 批处理优化
主流模型对比
| 模型名称 | 维度 | 特点 | 适用场景 |
|---|---|---|---|
| OpenAI Ada | 1536 | 通用性强 | 英文场景 |
| BGE | 768 | 中文效果好 | 中文场景 |
| E5 | 1024 | 开源免费 | 通用场景 |
向量数据库实践
Zilliz云服务实践
Zilliz作为Milvus的云服务版本,提供了更便捷的向量数据库部署和管理方案。
1 | # Zilliz云服务配置 |
Zilliz性能优化
分片策略
- 合理设置分片数量
- 根据数据规模调整分片大小
- 启用动态分片
资源配置
- 选择合适的实例规格
- 配置合理的内存比例
- 优化查询并发数
OpenSearch实践
OpenSearch支持向量检索和倒排索引的混合查询,特别适合需要结合全文搜索的场景。
1 | from opensearchpy import OpenSearch, RequestsHttpConnection |
高级检索技术
倒排索引与向量检索结合
在实际应用中,常常需要结合倒排索引和向量检索的优势:
预过滤策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def hybrid_search_with_prefilter(query_text, query_vector, filters):
# 先使用倒排索引过滤
prefilter_query = {
"bool": {
"must": [
{"match": {"content": query_text}},
{"terms": filters}
]
}
}
# 在过滤结果上进行向量检索
filtered_docs = elastic_client.search(body=prefilter_query)
doc_ids = [doc['_id'] for doc in filtered_docs['hits']['hits']]
return vector_search(query_vector, doc_ids)混合排序策略
1
2
3
4
5
6
7
8
9
10
11def hybrid_ranking(text_scores, vector_scores, alpha=0.3):
"""
结合文本相关性得分和向量相似度得分
alpha: 权重参数,控制两种得分的比例
"""
final_scores = {}
for doc_id in text_scores:
if doc_id in vector_scores:
final_scores[doc_id] = alpha * text_scores[doc_id] + \
(1 - alpha) * vector_scores[doc_id]
return final_scores
Rerank技术实践
使用Rerank技术可以显著提升检索质量:
1 | from sentence_transformers import CrossEncoder |
Rerank最佳实践
两阶段检索策略
- 第一阶段:向量检索召回候选集
- 第二阶段:Cross-Encoder精排序
性能优化
- 批量处理重排序请求
- 使用轻量级模型
- 缓存热门查询结果
质量提升方法
- 领域适应性微调
- 负样本增强
- 集成多模型结果
部署架构示例
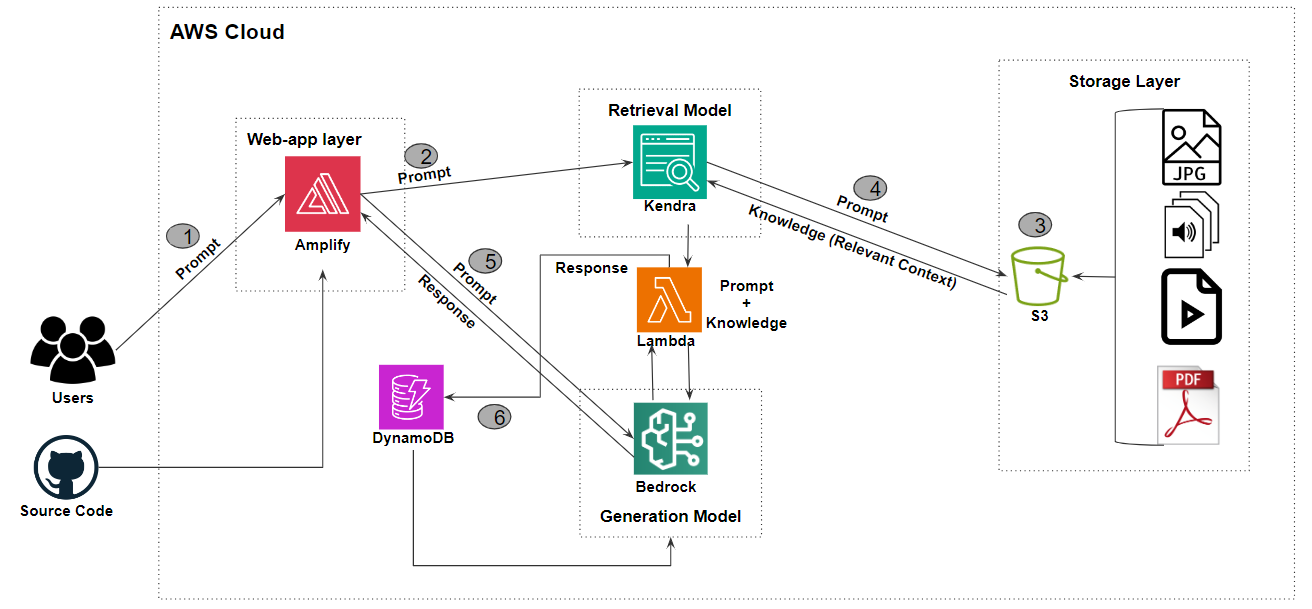
高可用架构设计
1 | [用户请求] |
性能监控指标
检索性能指标
- P95延迟
- 召回率
- 准确率
- QPS
资源使用指标
- CPU利用率
- 内存使用率
- GPU利用率
- 网络带宽
实践示例
基础环境搭建
1 | # 安装必要依赖 |
文档处理与向量化
1 | # 文本分块 |
检索实现
1 | # 相似度搜索 |
性能优化策略
1. 向量索引优化
- 使用HNSW或IVF索引
- 合理设置索引参数
- 定期重建索引
2. 缓存优化
- 实现多级缓存
- 热点数据预加载
- 结果缓存策略
3. 批处理优化
- 合理的批处理大小
- 异步处理机制
- 负载均衡
最佳实践建议
系统架构设计
模块化设计
- 解耦向量服务
- 支持横向扩展
- 服务监控机制
数据流优化
- 流式处理
- 并行计算
- 错误重试机制
生产环境部署
资源规划
- CPU/GPU配置
- 内存需求评估
- 存储容量规划
监控告警
- 性能指标监控
- 错误日志收集
- 服务质量监控
实际应用案例分析
1. 智能客服系统
技术架构
- 向量数据库:Milvus
- Embedding模型:BGE-Large
- LLM:ChatGPT
核心指标
- 平均响应时间:200ms
- 准确率:95%
- 召回率:90%
2. 企业知识库搜索
系统设计
- 分布式存储
- 实时索引更新
- 多模态支持
性能数据
- QPS:1000+
- 延迟:<100ms
- 准确率:98%
未来发展趋势
技术演进
- 小型化Embedding模型
- 多模态融合
- 自适应优化
应用拓展
- 跨语言检索
- 实时流处理
- 个性化推荐
总结与展望
Embedding服务作为RAG系统的核心组件,其重要性将随着AI技术的发展而进一步提升。通过合理的架构设计和优化策略,能够构建出高效、可靠的RAG应用。未来,随着新技术的不断涌现,Embedding服务将在更多领域发挥重要作用。